One row. Vector and SQL, together.
Dreambase co-locates your HNSW vector index with your SQL row data. One INSERT writes both. One query returns similarity-ranked results filtered by any SQL predicate. No second store to operate. No embedding job running behind your writes.
The dual-store tax
Pinecone + Postgres. Weaviate + RDS. The pattern is the same: write twice, sync forever, debug when they diverge. The code below is what every LLM team eventually ends up with — and what they wish they hadn't.
# Write to Postgres (structured data) pg.execute( "INSERT INTO docs (id, user_id, content)" " VALUES (%s, %s, %s)", [doc_id, user_id, content] ) # Generate embedding (separate service call) embedding = embed_api(content) # Write to Pinecone (vector store) pinecone.upsert( vectors=[(doc_id, embedding, {"user_id": user_id})], namespace="docs" ) # Hope they stay in sync... # (They won't.)
# One INSERT. Both columns. One transaction. db.execute( "INSERT INTO docs" " (id, user_id, content, embedding)" " VALUES (%s, %s, %s, %s)", [doc_id, user_id, content, embedding] ) # Query vector + SQL in one call rows = db.query( "SELECT * FROM docs" " WHERE user_id = %s" " ORDER BY embedding NEAR %s" " LIMIT 5", [user_id, query_embedding] ) # Always fresh. No sync needed.
How Dreambase works
One INSERT writes your structured columns and your float32 embedding array atomically. ACID guarantees cover both. The HNSW index updates in the same transaction.
The hybrid query planner sees both your WHERE predicates and your HNSW index statistics. It picks scalar-first when selectivity is high, ANN-first when it isn't. No hints required.
UPDATE a row and the vector column changes in the same commit. Retrieval queries run against the HNSW index of record — not a 15-minute-old snapshot from your last embedding batch.
What's inside Dreambase
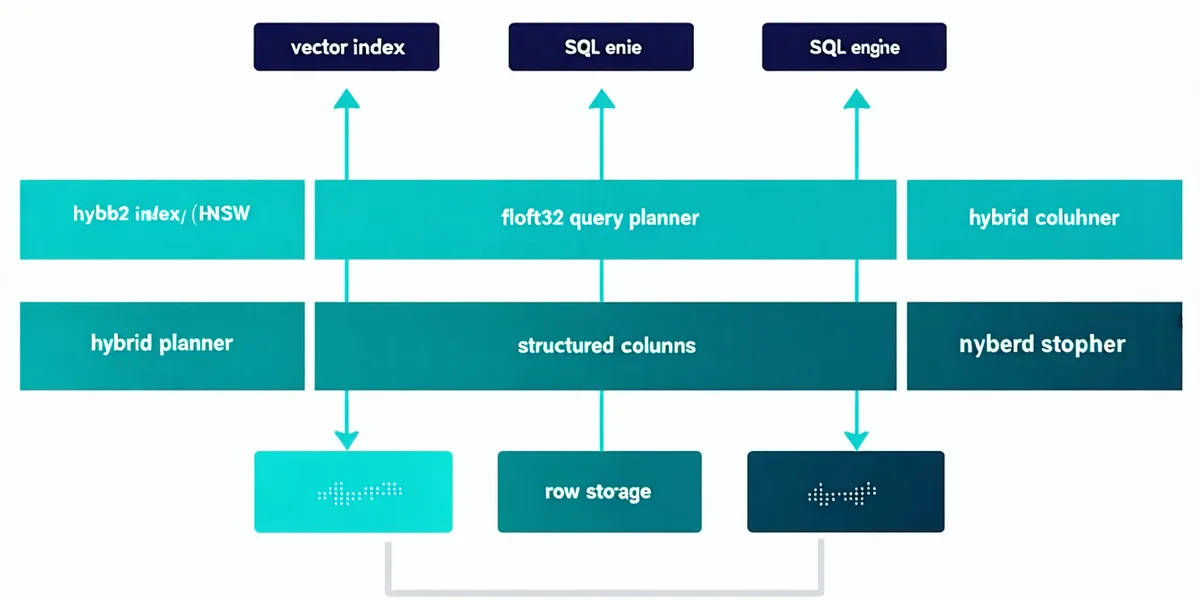
HNSW graph co-located on the same storage pages as the row data. ANN scans never cross a network boundary to a separate store. Supports M and ef_construction tuning per table.
Full PostgreSQL-compatible query planner: joins, window functions, CTEs, aggregations — on the same table that holds your embeddings. Any psycopg2 or asyncpg client connects without a new driver.
Cost-based planner runs scalar pre-filter when WHERE clause selectivity is above the crossover threshold (estimated from live index stats), ANN-first otherwise. Inspect the decision with EXPLAIN HYBRID.
Built for production LLM workloads
When a Confluence page or knowledge-base article is edited, the UPDATE hits one database and one transaction — the embedding is current before the next retrieval call. No separate re-embedding pipeline to schedule or monitor.
Tenant isolation in a single table: WHERE tenant_id = $1 ORDER BY embedding NEAR $2. The cost-based planner filters by tenant first (high selectivity), then runs ANN on that tenant's rows only — no per-tenant index sharding required.
Store conversation turns with embeddings alongside structured metadata (session_id, timestamp, role). Retrieve relevant context with WHERE session_id = $1 AND created_at > $2 ORDER BY embedding NEAR $3 — one query, no app-layer join between a vector store and a session table.
Queries that read like intent
The NEAR operator is a first-class ORDER BY clause. Combine it with any SQL predicate in one statement. No second query to a vector store, no application-layer result merge, no staleness check.
import dreambase db = dreambase.connect("postgresql://user:[email protected]/myapp") # Hybrid query: SQL predicates + vector similarity in one call results = db.query( """ SELECT id, content, user_id, created_at FROM documents WHERE user_id = %(user_id)s AND created_at > NOW() - INTERVAL '7 days' ORDER BY embedding NEAR %(query_vec)s LIMIT 5 """, {"user_id": "u_441", "query_vec": query_embedding} ) for row in results: print(row.content, row.created_at)
-- Hybrid query in pure SQL (PostgreSQL-wire compatible) SELECT id, content, user_id, created_at, embedding NEAR $1 AS similarity_score FROM documents WHERE user_id = $2 AND created_at > NOW() - INTERVAL '7 days' ORDER BY embedding NEAR $1 LIMIT 5;
import { connect } from 'dreambase'; const db = await connect({ url: 'postgresql://user:[email protected]/myapp' }); // Hybrid query: filter + rank in one round-trip const results = await db.query(` SELECT id, content, created_at FROM documents WHERE user_id = $1 ORDER BY embedding NEAR $2 LIMIT 5 `, [userId, queryEmbedding]); results.rows.forEach(row => console.log(row.content));
What engineering teams say
We had a Celery job that re-embedded documents on a 30-minute cron. Users would edit a doc and get stale retrieval for half an hour. Dreambase made that class of bug impossible — the vector is part of the row, so it's never out of date.
The thing I didn't expect: multi-tenant retrieval got simpler too. We were namespace-partitioning in Pinecone as a workaround. With Dreambase it's just a WHERE clause, and the planner handles the cost trade-off automatically.